Building a Truck Fleet Telematics App with Claude Code and a Local LLM

Diwa “Wawi” del Mundo
Founder & CEO · Apper Cloud Labs
We are currently building a truck fleet telematics application using Claude Code paired with a local LLM. The local model is Qwen 3.6 35B, running on an NVIDIA DGX Spark.
I wanted to share honest observations from the process because it changes how you think about agentic development. Not in a theoretical way. In the very practical sense of how you assign work, manage context, and protect your own attention.
Build context
The honest comparison with frontier models
Qwen 3.6 35B running locally is not as fast as frontier models like Claude Opus or OpenAI Codex. On complex reasoning tasks, you feel the difference. Response latency is higher. Very long context windows also take more time to process.
That matters. Speed affects flow. When you are deep in a build, a fast model can feel like it is keeping pace with your thinking.
But speed is only one dimension of the equation. Once you stop treating every token as a billable event, the whole working pattern starts to change.
| Dimension | Frontier hosted models | Local LLM on dedicated hardware |
|---|---|---|
| Latency | Faster on complex reasoning and long context | Slower, especially on larger passes |
| Reasoning depth | Stronger for hard planning and ambiguous decisions | Good enough for many implementation loops |
| Cost behavior | Token usage shapes how much context you provide | No per-token meter during local runs |
| Best role | High-stakes reasoning, review, difficult architecture | Iteration, exploration, refactors, background progress |
What local LLMs actually unlock
When you remove the cost-per-token constraint, your relationship with the agent changes. You stop optimizing every prompt around budget. You stop trimming context just to avoid overage. You can let the agent explore, iterate, and bring back a large amount of work without mentally converting output into spend.
For a project like telematics, that freedom matters. Fleet software has many moving parts: vehicle status, trip history, driver behavior, route exceptions, maintenance signals, alerts, and operational dashboards.
The agent can make multiple passes through those layers. It can try different approaches. It can refactor after seeing the shape of the code. It can produce a rough version, inspect it, and improve it without creating cost anxiety on our side.
Local LLMs change the economics of iteration. That changes the behavior of the human using the agent.
The work becomes more sustainable
There is a real cognitive cost to staying deep in an agentic build. Context overload is not just a model problem. It is a human problem too.
When you are constantly reading agent output, checking files, adjusting prompts, and steering implementation, your brain keeps carrying more and more state. That can be productive for a while. Then it becomes tiring.
With a local setup running continuously, you can queue a meaningful task and step away from the computer. You come back to progress instead of burnout. That sounds simple, but it is one of the most underrated benefits of this setup.
0
per-token anxiety during local model runs
35B
Qwen parameter class used for the local agent loop
3
core telematics areas: fleet, driver, route
Where this fits in a real AI engineering workflow
I do not see local LLMs on dedicated hardware as a full replacement for frontier models. They serve a different purpose.
- Use frontier models when the reasoning is hard, ambiguous, or high-impact.
- Use local models when the task benefits from many implementation passes.
- Use both when you want strong planning plus low-friction execution.
- Treat the local model as a durable build partner, not a magic shortcut.
The workflow feels closer to having a patient junior engineer available for extended exploration. You still review the work. You still decide what matters. But you can ask for more attempts without feeling like every iteration needs to justify itself financially.
What the app is starting to look like
The truck fleet application is still taking shape, but the core product direction is visible: fleet visibility, operational monitoring, and dispatch intelligence in one working surface.
These screenshots are from the build process. They show the application moving from agent output into a concrete interface that a fleet operator can inspect, question, and eventually use.
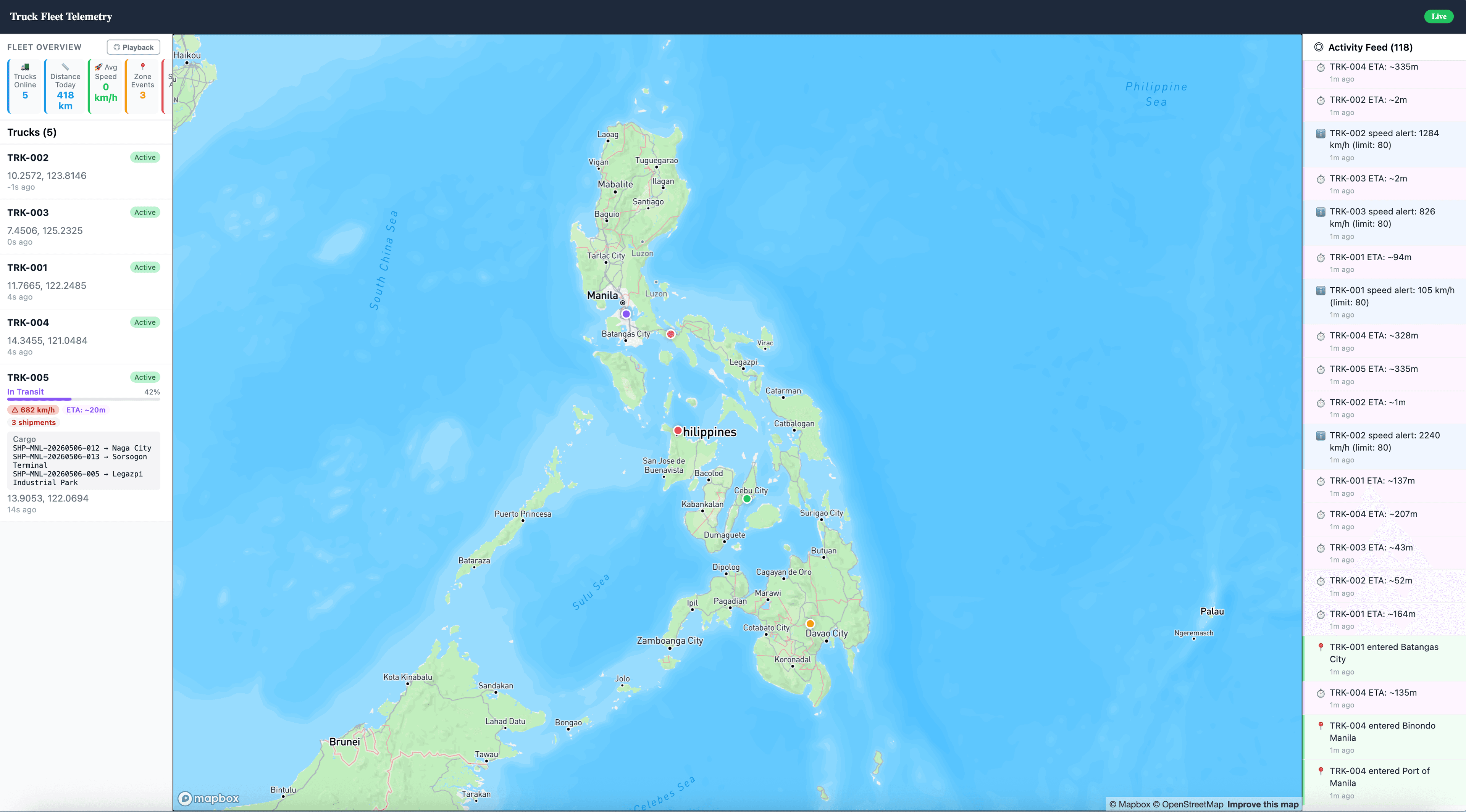
The practical takeaway
Local LLMs on hardware like the DGX Spark are not about beating the fastest hosted model. They are about creating a low-friction environment where agents can work for longer, iterate more freely, and support a healthier development rhythm.
For builders, that matters. The technical gains are real, but the human gains may be just as important. You can step away. You can return with fresh eyes. You can let the machine absorb more of the repetitive exploration while you stay focused on judgment.
We are still building
The app is taking shape, and we are learning a lot about what agentic development actually feels like when cost is removed from the conversation. That may be the bigger lesson here: when the token meter disappears, the way you collaborate with software starts to feel different.
Diwa “Wawi” del Mundo
Founder & CEO, Apper Cloud Labs
Wawi holds all 14 AWS certifications alongside CISSP and CCSP — one of the most credentialed cloud architects in the Philippines. He founded Apper Cloud Labs in 2019 to make enterprise-grade cloud and AI expertise accessible to Philippine SMBs.